
As your app’s audience grows, bots and scammers become increasingly interested in your app. When we needed a scalable tool for breaking bots and users apart, we found it way too expensive to cover all the bases with reCaptcha, which we were already using. So here is what we did.
How It All Began
FunCorp develops UGC entertainment applications, and bots are a common bane of such products. As our flagship — iFunny — grew, we started seeing active users who were not looking at their meme recommendation feeds. They would actively follow other users and like and comment on their content.
The comments were often just ads. However, sometimes bots had links in their profiles that led to phishing websites rather than ads. We care about user safety and don’t want the user experience to suffer, so we started thinking of ways to solve the problem.
Soon, we identified a pattern:
- Someone creates an account and sets a clickbait avatar for the profile: usually a photo of a pretty girl.
- This account starts liking content, leaving comments, following users, or adding them to chats.
- Users see the avatar and click on the profile, which features a link to a malicious website.
We have learned to detect and automatically ban these bots, but they still have time to mess things up in the time it takes to deactivate the account. That’s why we have to be proactive!
To successfully solve the bot problem, you need to ensure that the cost of bypassing a CAPTCHA is higher than the expected profit the cybercriminal could get. Hence, we needed an easy-to-deploy solution that we could scale up to cover the entire application at a low cost. We were already using reCaptcha by Google, but it was hooked up to a minimal number of endpoints with relatively forgiving rate limits. The main drawback of this solution was scaled pricing, which depended on the number of requests per month.
We decided that it was a good solution, but with an expensive price tag, especially for Enterprise.
We needed to increase the coverage of endpoints and change the rate limits. Given our growing audience, we decided to limit the request frequency using our proprietary tools.
Increasing the Number of Endpoints and Changing Rate Limits
We asked our BI Department to provide details on how often users make requests using all input controls at specific intervals, e.g.:
- 10 seconds
- 20 seconds
- 1 minute
- 2 minutes
- 5 minutes
- 10 minutes
- 20 minutes
- 1 hour
- 2 hours
- 1 day
We then asked for endpoint call frequency samples and distributed them by percentiles. Our task was to identify edge cases. For example, if users like content nonstop, this likely means driving up the numbers to a fake engagement. This behavior seems unusual, and there should not be too many accounts like that. And that was the case — these users were in the 99 percentile. That is, only 1% of users liked the content nonstop.
This is what the spread looked like for the likes: the X-axis stands for requests per minute, while the Y-axis represents the share of users that made X or fewer requests per minute.
Having done the same for the other endpoints, we defined a request frequency limit. When a user (or a bot :)) goes over it, we ask them to solve the CAPTCHA.
Now we had to figure out what that CAPTCHA would be.
Picking a Scalable CAPTCHA
We looked into several basic CAPTCHA forms.
Image-based CAPTCHA
Basically, this could be an internal equivalent of Google’s reCaptcha, where the user has to select the right image(s) from several ones. This would require downloading and creating your own image database, though.

This solution is very difficult to develop and support.
Mathematical CAPTCHA
This one involves solving a simple equation. It is easy to develop, but it was ill-suited for our core business.

We are all about memes, not math.
Interactive CAPTCHA
More often than not, this CAPTCHA asks you to rotate or slide part of the image to, for example, put the picture together.
This solution is difficult to deploy, and users with older devices may experience issues.
Audio CAPTCHA
This one is the good ol’ text-based CAPTCHA converted to speech by a robot. Besides being difficult to develop, this one is also difficult to solve.

Furthermore, a lot of people like to keep their phones on silent these days.
Text-based CAPTCHA
There is an undying classic: barely legible text on a picture, where the user has to write it down. Even though AI has recently been doing a much better job at text recognition than humans, this is a quick and easy solution. In addition, users are accustomed to it, and the pictures are easily resizable to fit any screen.
After some discussion, we settled on this option because it is easy for users to understand and easy for us to develop and deploy. Although there are many text-based CAPTCHA generators available for free, we developed our own solution that is easy and fast to configure.
Preparing the Client
This is what the default process for displaying a CAPTCHA looks like:
- Client sends a request to the desired endpoint. This might include sending a like/dislike or querying the user’s profile.
- Server evaluates request frequency and decides that the most recent request is over the limit.
- Instead of processing the request, the server sends an error and instructs the client to display a CAPTCHA.
- Client displays a CAPTCHA with a field to enter text, get a new CAPTCHA, and submit a solution.
- User solves the CAPTCHA.
- Server returns a response saying that the CAPTCHA was correctly solved.
- Client sends a second request.
- Server processes the request.
We knew that our clients were not ready to handle CAPTCHA across all endpoints, because not all of the app screens could respond to Error 403. Therefore, the first task was to make sure that Error 403 was handled by all screens and all input controls on the clients. It was important to develop reactivity for all input controls, but also design the app’s behavior for when a user fails CAPTCHA or refuses to solve it.
We started with this task so that the users (bots included) would upgrade to the current app version ASAP and could no longer determine which version introduced CAPTCHA.
Other Things to Consider During Preparations
Configuring the CAPTCHA Generator. We built in the ability to customize:
- Fonts
- Background colors
- Color range used for CAPTCHA letters
- Letter rotation relative to the vertical axis
- Level of noise applied to images
- Number of strikethrough lines that interfere with text recognition
And it was a good thing that we did — we had to tweak these parameters over and over again to make the CAPTCHA too difficult for computer vision to recognize, yet easy for a human to read.
Rate Limiter. We log successful requests in Redis, storing who made them and what kind of a request they were. Depending on the request type, the object’s lifetime value is set and a sliding window is generated. Every new request is checked to see exactly how many requests of the same type are currently stored in the cache for that user. If the user goes over the limit, we ask them to solve the CAPTCHA.
Changeable Rate Limits and CAPTCHA Types. We developed a series of configurable parameters to share the workload between the old (reCaptcha) and the new CAPTCHA, depending on how critical the control input is and how often it is triggered. For example, we always ask new users to solve a reCaptcha when they sign up. As for the likes, users will have to solve the new text-based CAPTCHA if their client sends requests nonstop.
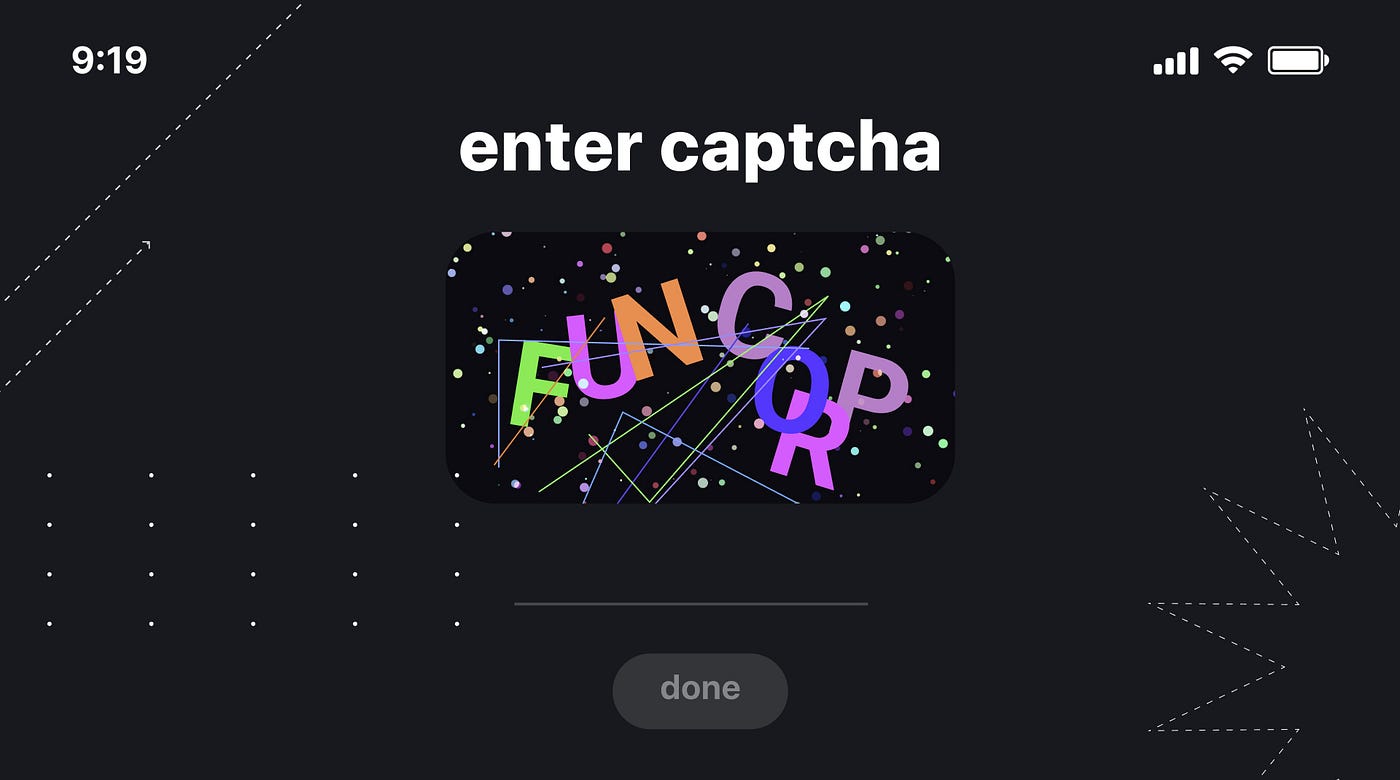
Design and Targeted Rates for CAPTCHA. The module that displays a CAPTCHA follows the overall design of our app:
This is what our CAPTCHA looks like.
The main issue is to tweak the difficulty of CAPTCHA. If it is too hard, our product metrics will suffer, if too easy — even the simplest algorithm will bypass it. So, before rolling out the new CAPTCHA for all users, we decided to check its performance.
How A/B Testing Helped Improve our CAPTCHA
So, we needed to make sure that the new CAPTCHA would reduce bot activity but leave ordinary users unaffected by the change. We launched an experiment on a fraction of the iFunny audience and monitored the following parameters:
Product Metrics: here we keep track of how the users are affected by the change and whether they use the app any less.
- Retention
- Likes Rate
- Comment Rate
- Scroll Reach Rate
The test would be successful if the product metrics did not decline.
Technical Metrics: these are the metrics for the CAPTCHA itself, both summarized and broken down by each endpoint. A high CAPTCHA failure rate for humans (not bots) would hurt product metrics. That is why we kept track of the following:
- Total number of CAPTCHA events
- Number of CAPTCHA events per user
- CAPTCHA success rate
- Rate at which users refused to solve the CAPTCHA
For the sake of easier tracking, we focused on the input controls that showed a CAPTCHA every time for the first request. We expected the CAPTCHA success rate to be at least 50%.
The first iteration of the experiment demonstrated the following:
- The change had no negative impact on product metrics, meaning that the rate limits were on point. However, following the test, we modified some limits that were too high on several endpoints.
- CAPTCHA events, as expected, have doubled.
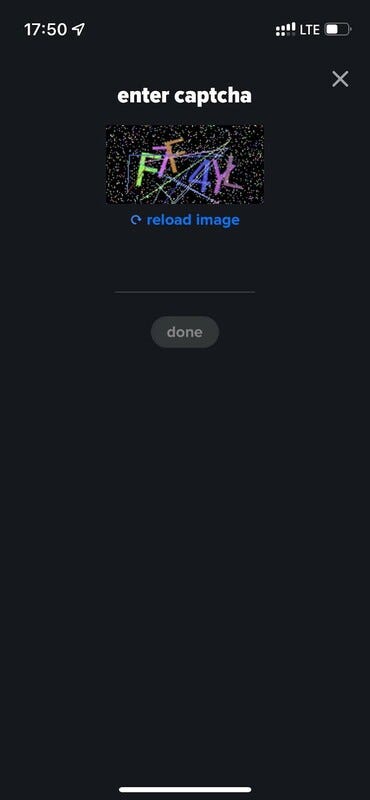
- CAPTCHA success rate was too low, meaning that it was too complicated. Feedback from employees who took part in the test also supported this. Therefore, we enabled advanced logging for failed CAPTCHA cases as follows: expected text — submitted text — CAPTCHA image.
I wonder if you can decipher some of these :)
We also detected some IPs and accounts that were shown CAPTCHA prompt very often but had zero success rate. We examined these cases in terms of behavioral analysis to determine the pattern for blocking such users.
After a few adjustments, we repeated the experiment with a different sample group so as to rule out the influence of the previous iteration. Our targets remained the same.
After the second experiment, we realized that we definitely need to optimize the CAPTCHA generator. Users often encountered the following issues:
- Letters were too close together.
- Colors were too faint compared to the background.
- Angling of the letters was occasionally too high, leading to confusion.
Moreover, users often confused uppercase and lowercase letters. We adjusted the character color range, made CAPTCHA case-insensitive, and tweaked other parameters.
However, the number of blocked bots has hardly dropped over two weeks. CAPTCHA couldn’t do what it was supposed to do. But we already knew how to fix this.
How to Deal with Bots?
We came up with this idea because we saw a high concentration of CAPTCHA requests for a group of users with the same IP in the first iteration of the experiment. Many bots seemed to be part of a network. In this case, a single bot could stop working when it received a CAPTCHA prompt and wait until the request rate was below the limit, while other bots in the network continued to work.
Here’s how our IP address control mechanism works:
- Monitor request rates for IP addresses rather than just for users
- If the request rate goes over the limit, then all users with the same IP will be prompted to solve the CAPTCHA.
- If the request rate goes over the limit, new users with the same IP will also be prompted to solve the CAPTCHA.
- Each user will have to solve the CAPTCHA to regain access.
In this case, the bots will have to constantly change their IPs, but we will ban them on a new IP if they go over the limit.
Simply showing CAPTCHAs when a user exceeds the rate limit will not save the product from the scourge of bots. As you can see, we needed more advanced logic, even going as far as to temporarily block users if they refused to solve the CAPTCHA. After we launched the IP ban and ran another iteration of the A/B test, we achieved the following:
- Product metrics did not fall.
- The number of events increased twofold, compared to the control figures.
- CAPTCHA success rate was 60%.
- The number of blocked bots dropped by 40%.
We rolled out this solution for 50% of our users. Once we checked the effect of the new CAPTCHA on metrics again, we rolled it out for 100% of the audience.