
This article explains how you can automatically divide a dataset of images into clusters classified by qualitative contextual feature, thanks to embeddings from the much talked about neural network called CLIP created by Elon Musk’s company. I will give you an example using the content from our iFunny app.

Clustering is considered an unsupervised task, and this means that there is no explicit labeling of target variables, i.e., there is no “teacher.” We load a dataset of images in our case, and we want to have it randomly but qualitatively divided into clusters.
For example, a set of animal images can be divided into clusters by species, by stripes, by several paws, or other features. In any case, we expect to have a clear logic for labeling, which can be further used for different tasks.
This article will tell how we have built a logical clustering using the HDBSCAN library and vectors from the CLIP neural network and our results.
About the CLIP Neural Network
In January 2021, Elon Musk’s company OpenAI released a neural network called CLIP (official website and code on GitHub). It was trained to generalize many categories that can be used further in different ML tasks. It has no class labeling for a particular task, but pairs of images and their text descriptions are in one space. Hence, the main advantage is that this network can be used in image classification tasks even without zero-shot learning.
The CLIP neural network is trained on 400 million pairs of images and text, each of which is fed to the input of the neural network and combined with other pairs in a batch. Then the grid is trained to predict which picture pairs in the set are actually similar. Through this process, vector representations in the text and picture pairs converge during training.
The trained model allows obtaining image-text embeddings simultaneously. It means that images and text can be compared in a single space. In fact, it will enable combining categories and classifying images by more complex text descriptions.
Here is an example. Previously, when applying training with a “teacher,” models distinguished mostly only simple and large categories like “cat” or “dog. Now they can distinguish lying cats from jumping cats and much more. It is possible to determine images by style, famous personalities in the shot, and several objects. Many combinations like these work without additional training and out of the box.
It works the following way: the neural network is fed an image and text, and it returns vectors of the image and text. Then you can calculate the cosine distance and understand how similar the text and the image are. In the task of classifying images, a class can be chosen by the closeness of image vectors and text description of the type:
 Source: OpenAI blog
Source: OpenAI blog
CLIP has an Image Encoder and a Text Encoder that convert the data into vector space and predict which images have been linked to which texts.
To cluster images in iFunny, we do not use texts, but we use Image Encoder, which outputs content-rich vectors describing the picture in a multidimensional space of features.
In fact, we only take this part from CLIP:
 Source: OpenAI blog
Source: OpenAI blog
Processing image clustering
We need to collect a vector I(x) for each dataset image and then cluster these vectors.
In a general way, clustering can be represented as follows:

A set of points/vectors in some space needs to be divided into n clusters. In our case, we take vectors from the CLIP image model. The picture shows a simple example in two-dimensional space, but the CLIP model gives a vector with a length of 512 features, which is quite a lot for standard clustering algorithms.
In such cases, it is worth using downscaling algorithms such as PCA, TSNE, or UMAP. We use the HDBSCAN library for clustering based on the algorithm with the same name.
I will not present all of the training code as it is specific to our tasks, but I will describe the necessary steps to reproduce the clustering on your data.
- After collecting the dataset, we need to assemble a vector from the CLIP model for each image. To do this, install the CLIP library and use only the function encode_image. Prepare the images in PyTorch.Tensor beforehand using Pillow (Python Image Library) as it is done in the CLIP library itself.
image = prepare_pil_image(image, transform).to(device)
image_features = self.model.encode_image(image).cpu().numpy()
We collect image_features for all images of the dataset.
In the output, we get an array sized [n, 512], where n is the number of images of the dataset, and 512 is the number of features for each image from the CLIP model. Then we divide this array into train_embeddings and test_embeddings.
- Next, we use the library UMAP-learn. With its help, we train and reduce the size to 2–5 features. Hyperparameters are given as an example. Most likely, the best result will be achieved with other values for your dataset.
dimension_model = UMAP.UMAP(n_neighbors=70,
n_epochs=300,
min_dist=0.03,
n_components=5,
random_state=35)
train_clusterable_embedding = dimension_model.fit_transform(train_embeddings)
- Then, we make clustering on the scaled-down vectors. To do this, we create a model HDBSCAN, train it and collect information on which picture corresponds to which cluster and the probability of each.
cluster_model = hdbscan.HDBSCAN(
min_cluster_size=1000,
alpha=2.,
cluster_selection_method=”leaf”,
prediction_data=True
)
cluster_model.fit_predict(train_clusterable_embedding)
train_labels, train_probabilities = hdbscan.approximate_predict(cluster_model, train_clusterable_embedding)
test_labels, test_probabilities = hdbscan.approximate_predict(cluster_model, test_clusterable_embeddings)
In the test_clusterable_embeddings, you can estimate the clustering quality on new data.
Results
In total, we had a dataset of 150,000 images after removing duplicates. As for the time spent, it was approximate as follows:
-
Training UMAP and HDBSCAN — about 2 hours.
-
Clustering in production — 1–2 seconds per 1 image.
Now let’s look at the clusters we got in our experiments. There turned out to be very interesting and representative categories:
Memes:

Food:

Motivational images:

Along with that, other specific clusters were formed: animals, politics, 4chan, anime, Twitter screenshots, iFunny app screenshots, jokes about the United States and other countries, selfies.
An interesting fact is that one of the categories created by the clusterized Doge memes, the famous Shiba-Inu dog:
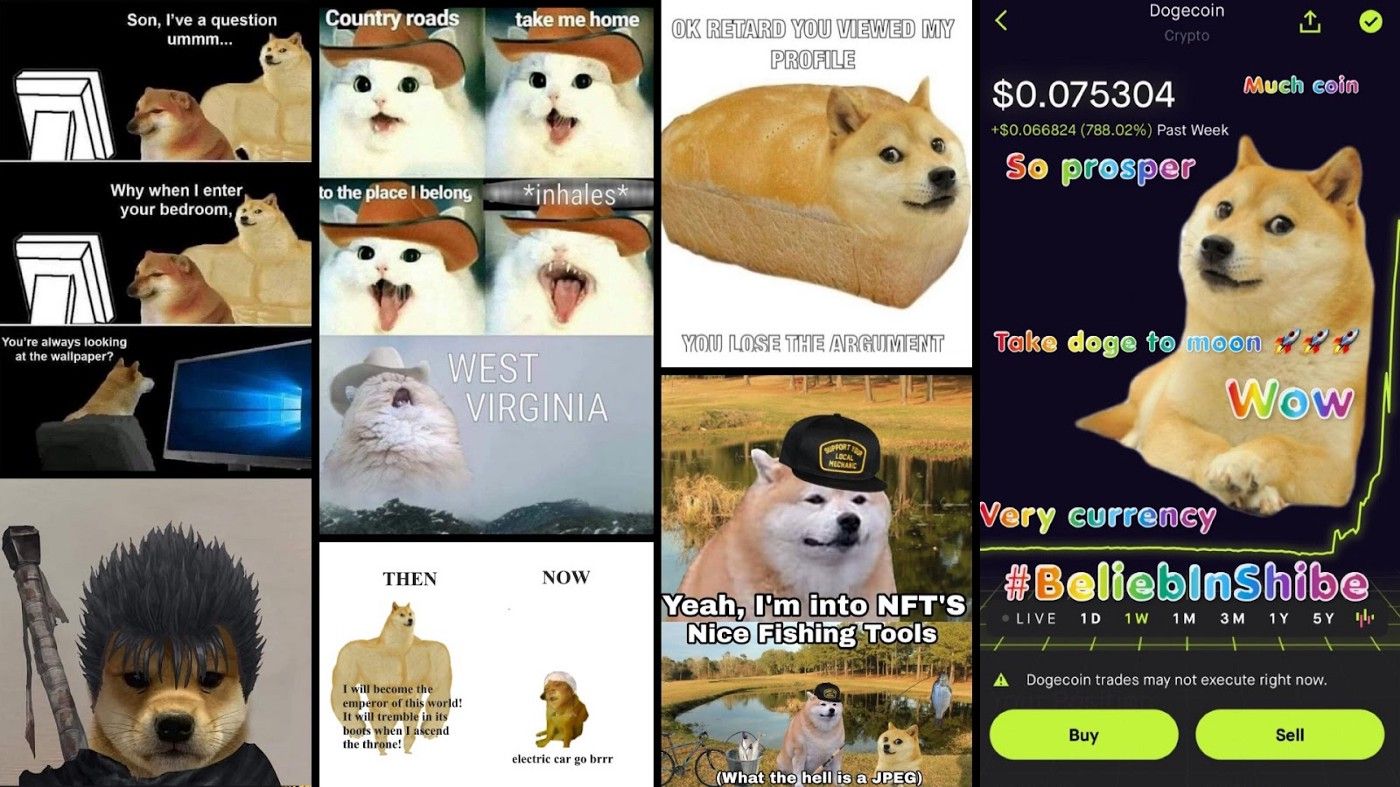
Disadvantages of the approach
-
It’s hard to get quality clustering. We experimented with UMAP and HDBSCAN parameters, but there are still mistakes and some complex content falls into the cluster “other”.
-
The quantity and logic of the clusters can vary on random parameters. But if you know exactly what classes you want to divide the images into, perhaps the best solution is to label the images and apply fine-tuning to the same CLIP model.
-
Models require time and memory in the inference phase. In order to speed up the production, you can use GPU.
Where you can use this approach
However, there are also advantages. Here are some ideas where you can apply this approach of content clustering:
-
For content research. You can take the content of one category (or one group of users) and see what clusters to divide it into. This is how you can better understand your audience.
-
To get preliminary classes for further labeling. For example, if you need only animals, you can take them from the cluster “animals”, but remove clustering mistakes at the labeling stage. This will speed up labeling time.
-
To obtain features for other models, e.g., recommendations. Even with clustering mistakes, the division mostly looks logical and accurate. Thus, it is possible to improve the metrics of content recommendation in the feed.
-
For quick experiments with one content category. You can take, for example, a food cluster and make a search button just for food photos.
Conclusion
The CLIP model gives image features of high quality, from which you can get clustering that truly reflects the logic and categories within your dataset. By combining UMAP and HDBSCAN you can easily get an average number of quality clusters (10–30) with almost no overlap.
All in all, we were happy with the results. This clustering can be done without labeling, and the clusters you get can be used in other tasks.